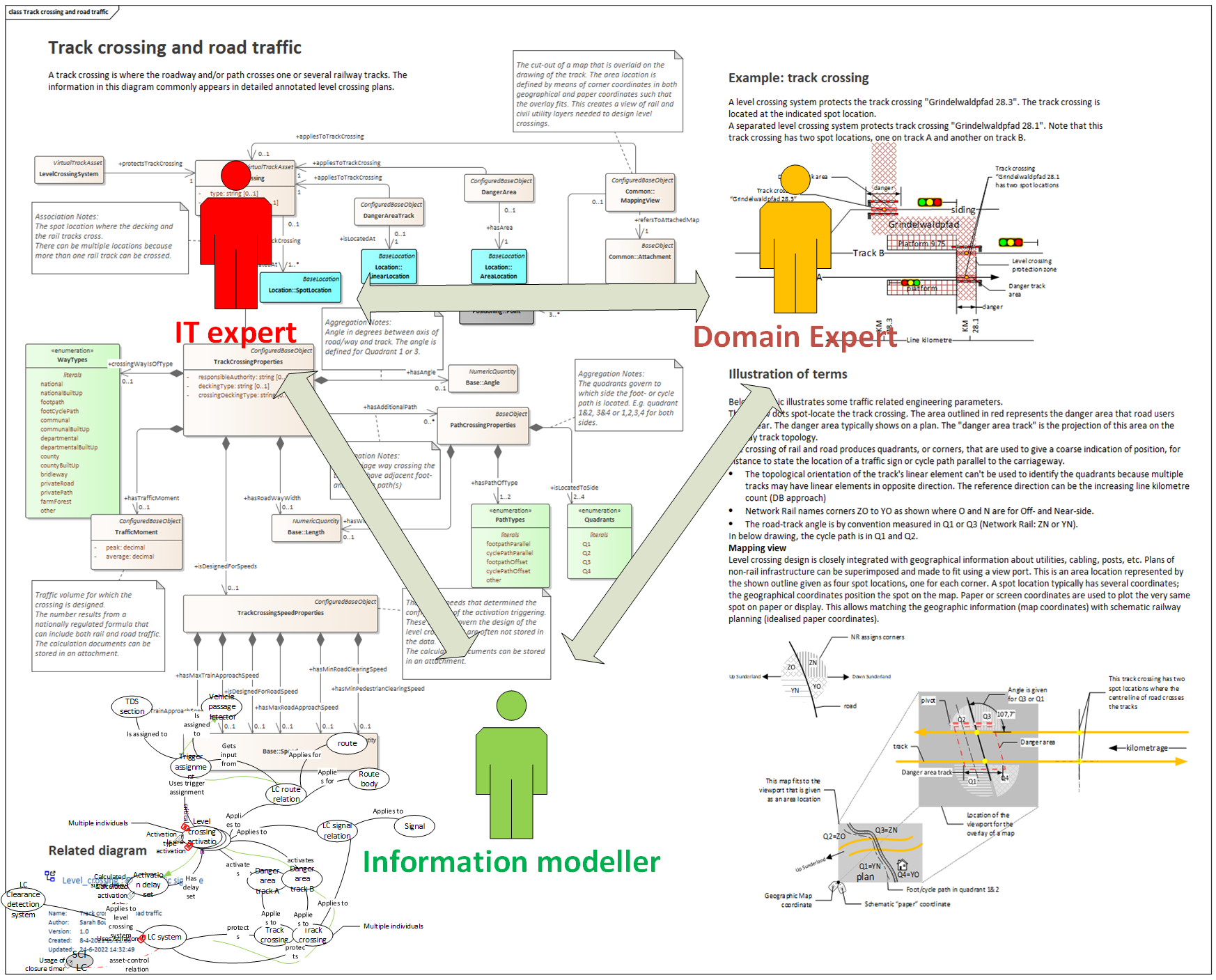
Below graphic shows the three experts and how their concerns can be united in a diagram.
The domain expert to the right will draw a sketch and “paint in words” what we’re looking at. In this case it’s about railway crossings. The information modeller at the bottom will cast the wording into a UML class model. The IT developer turns the UML into code.
There’s nothing special to this diagram except the presence of illustrations and explanatory text. Because the UML and illustrations are kept close to each other, the model is easily reviewed by all three kinds of experts. Grouping UML with text and figures is much simpler than maintaining UML separate from documents.
The EA AddOn enhances EA’s built-in HTML-publishing function by adding a landing page listing the triples.
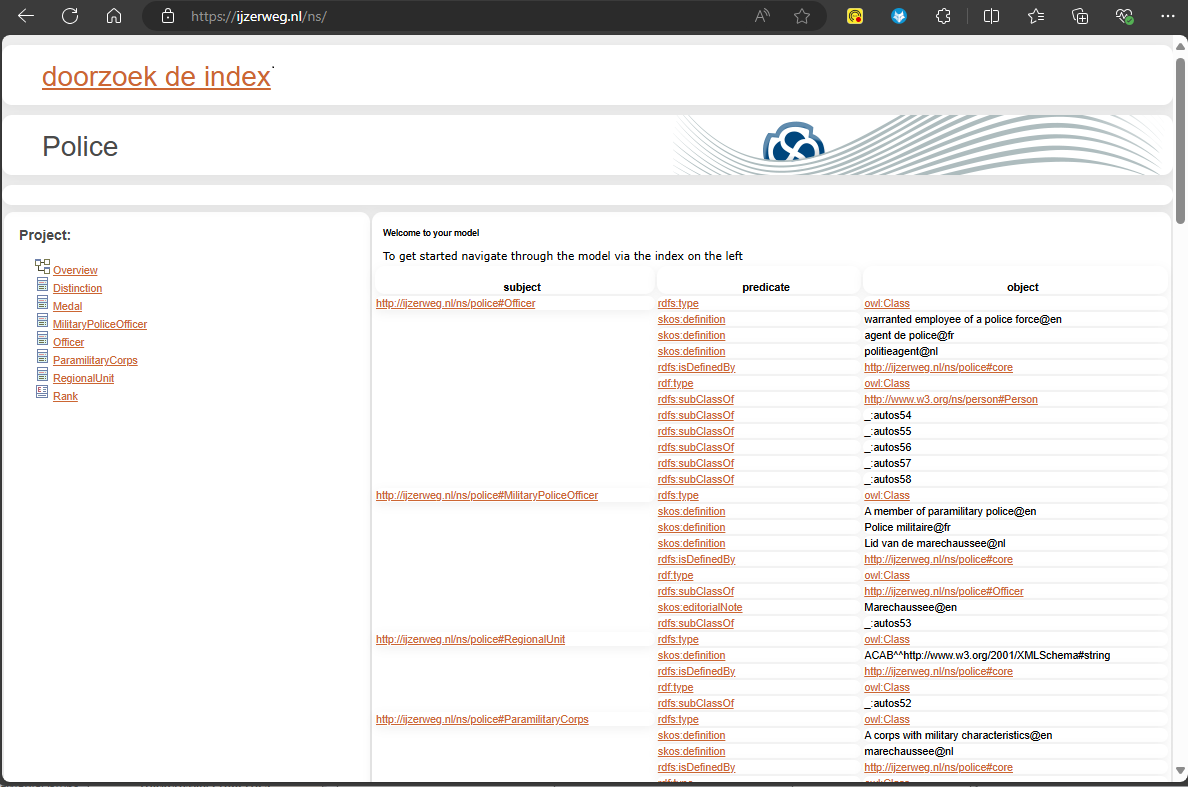
Below screenshot shows the landing page with a list of triples.
The user can publish the generated HTML to his website such that the URI’s actually have a home. An URL such as http://ijzerweg.nl/ns/police#MilitaryPoliceOfficer will lead to the shown landing page.
So by clicking a hyperlink, the user gets the context that’s originally defined in the model.
This is substantially richer than plain triples or plain HTML. More important, the UML seamlessly fits the HTML.
The user, whether domain expert, IT developer or modeller, doesn’t waste time switching between tools.
The “doorzoek de index” takes the user to a searchable index that lists the UML elements defined in the model. Start typing in the Search box and a number of suggestions appear. The user can browse and look around the model.
The search capability is another important enhancement with respect to the standard EA HTML publication.
Leave a Reply